Quando olhamos para a Internet, a Internet olha-nos de volta.
Há algumas questões que têm vindo a incomodar alguns de nós aqui no SPAC. Na era da Web personalizada, como é que a experiência de navegação de um ávido consumidor de notícias falsas difere da de outra pessoa? Mais especificamente, como é que isso afecta o conteúdo de terceiros apresentado nos sites? E será que um histórico de navegação repleto de desinformação leva a resultados diferentes nos motores de busca? Nesta publicação do blogue, vou discutir brevemente por que razão o estudo do rastreio em linha pode ser benéfico para melhorar o nosso conhecimento sobre a propagação da desinformação, bem como os desafios associados à sua realização de forma ética.
Atualmente, é do conhecimento geral que o conteúdo direcionado por terceiros é um dos principais mecanismos de financiamento dos sítios Web. A segmentação comportamental de conteúdos permite que as empresas e outras entidades apresentem os seus conteúdos aos seus públicos-alvo através de motores de busca (pesquisas patrocinadas) ou de sítios Web (anúncios ou conteúdos patrocinados).
Para orientar os utilizadores, as redes de publicidade e outros fornecedores de conteúdos precisam de criar perfis de utilizador que exigem quantidades significativas de dados do utilizador, desde a localização geográfica do utilizador, que pode ser inferida a partir do endereço IP, até aos interesses dos utilizadores, que são tradicionalmente inferidos a partir do histórico de navegação e de outras fontes de dados. Embora os sítios Web pareçam ser entidades unitárias armazenadas num servidor Web, alguns dos conteúdos apresentados nos clientes dos nossos programas de navegação, por exemplo, os tipos de letra ou algumas imagens, quando visitamos um sítio Web, provêm de terceiros incorporados. Se tiverem acesso a scripts nos sítios Web, os terceiros podem seguir os utilizadores através dos sítios Web, atribuindo-lhes identificadores únicos. Normalmente, estes identificadores únicos são sequências arbitrárias que são armazenadas no dispositivo do utilizador e associadas a domínios de terceiros(cookies) ou calculadas, utilizando scripts JavaScript, a partir de propriedades do dispositivo do utilizador que o tornam identificável de forma única(impressão digital).
Não se espera que os sítios Web de desinformação sejam diferentes. Longe disso. Anedotas de adolescentes dos Balcãs e de pais suburbanos norte-americanos sugerem que esta pode ser uma indústria lucrativa. Um relatório recente da ONG Global Disinformation Index, que utilizou uma amostra de 480 sítios Web de desinformação (seguidos durante um período de 5 meses), calculou que estes sítios estavam a ganhar milhões em receitas de publicidade. Da mesma forma, tem havido vários relatos de conteúdos direccionados que estão a ser utilizados para espalhar desinformação, como o conteúdo patrocinado direcionado repetidamente publicado na Newsweek sobre a utilização de prata coloidal para tratar a covid-19. A nossa própria investigação preliminar sugere que o rastreio em linha pode ser mais difundido em sítios Web de notícias falsas na maioria das categorias de rastreadores de terceiros, mas especialmente quando se trata de rastreadores associados a redes de publicidade.
No entanto, o rastreio em linha e a forma como este afecta a experiência dos utilizadores em sítios Web e motores de busca têm recebido muito menos atenção nos debates políticos e académicos sobre o tema da desinformação do que outros temas, como o papel das plataformas de redes sociais. Por exemplo, se analisarmos o número de artigos que mencionam palavras-chave relacionadas com a desinformação2 juntamente com palavras-chave associadas aos meios de comunicação social, à privacidade, à publicidade e aos motores de pesquisa numa base de dados de artigos noticiosos como a mediacloud ou em servidores de pré-impressão como o arxiv, verificamos que os artigos que correspondem a palavras-chave relacionadas com a desinformação e os meios de comunicação social contêm uma proporção significativa dos resultados.
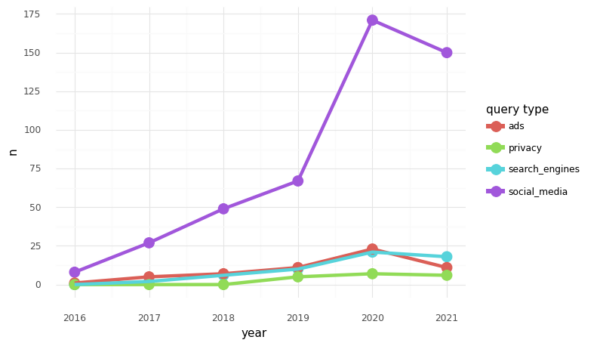
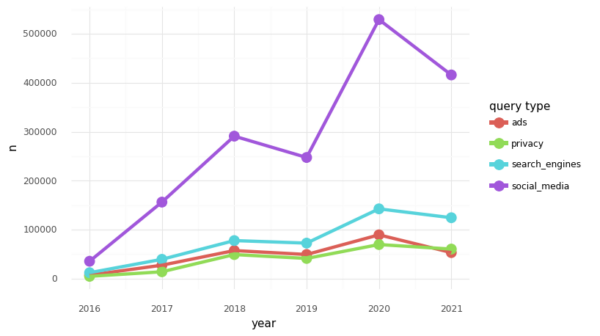
Figura 1: Número de artigos (a nível mundial) que correspondem a palavras-chave de desinformação e palavras-chave associadas a anúncios, privacidade, motores de busca e redes sociais.
Mas como é que se estuda o rastreio em linha e as bolhas de filtragem que lhe estão associadas? E como é que se faz isso respeitando a privacidade? Parece haver três formas, cada uma com prós e contras subjacentes. Em primeiro lugar, podemos pedir às pessoas os seus dados ou seguir os utilizadores através de extensões Web instaladas voluntariamente. No entanto, as normas éticas de investigação exigem que esta abordagem só seja adoptada se preservar verdadeiramente a privacidade e, embora tenha havido vários desenvolvimentos positivos nesta área, continua a ser um limite ético crucial a ter em conta. Uma segunda abordagem envolve a utilização de bots para imitar os utilizadores e rastrear a Web do ponto de vista dos "consumidores de desinformação" sem utilizar quaisquer dados pessoais reais. No entanto, esta abordagem tem o custo de um risco acrescido de deteção de bots por rastreadores e nunca será "a coisa real". Uma terceira opção, claro, é ter um bom amigo em lugares de destaque (como o Google).
Escusado será dizer que a investigação da desinformação nas plataformas das redes sociais continua a ser crucial. O nosso objetivo aqui é complementá-lo, perguntando o que acontece quando alguém clica naquele sítio Web de notícias falsas no seu feed das redes sociais e decide "fazer a pesquisa".
by José Reis